How to implement a model in Sorrel
This tutorial provides an introduction to wrapping a model for use with Sorrel. While this tutorial will provide an introduction to the base model interface, Sorrel also includes existing pre-built IQN and DDQN models, interfaces for models written in Jax or PyTorch, and a simple interface for human input.
For more information about the base model classes, please consult the documentation for the SorrelModel class.
Base model functions
The SorrelModel is an abstract class intended to be as minimal and flexible as possible. It can wrap any kind of model as long as it implements a method for taking an action, by overriding the method take_action():
@abstractmethod
def take_action(self, state: np.ndarray) -> int:
"""Take an action based on the observed input.
Must be implemented by all subclasses of the model.
Args:
state: The observed input.
Return:
The action chosen.
"""
pass
At a minimum, this method is called whenever an agent takes an action in the environment using the Agent.transition() function. It can additionally be called when a model completes a training step using the train_step() function (described below). The base class takes a single input, a state (generated from an environment when an agent makes an observation using sorrel.observation.observation_spec.ObservationSpec.observe()) and yields an output int that corresponds to the action taken.
Many models have an exploration parameter  that dictate the chance of taking a random action. The base model has a convenience function set_epsilon() to allow this value to be updated across time:
that dictate the chance of taking a random action. The base model has a convenience function set_epsilon() to allow this value to be updated across time:
def set_epsilon(self, new_epsilon: float) -> None:
"""
Replaces the current model epsilon with the provided value.
"""
self.epsilon = new_epsilon
Trainable models
Although not all models require training (e.g., a model that implements a preselected action policy, or a model that accepts human input), it also supports wrapping the model training loop using the function train_step():
def train_step(self) -> float | Sequence[float] | torch.Tensor | jax.Array:
"""Train the model.
Return:
The loss value.
"""
return 0.0
Custom implementations can return a single loss value or a sequence of values, including Jax arrays and PyTorch tensors. By default, the function returns 0 if no specific loss procedure is computed.
Additional functions
Some models require additional updates or changes outside of model training (e.g., to update parameters when using both a local and target network). The base class implements two functions start_epoch_action() and end_epoch_action() that can perform any similar actions before or after an epoch.
def end_epoch_action(self, **kwargs):
"""Actions to perform after each epoch."""
pass
Using the replay buffer
By default, SorrelModel has a replay buffer Sorrel.buffers.ClaasyReplayBuffer that can store up to memory_size states. This buffer can allow the model to:
Add states to the model’s replay buffer
Sample minibatches from the model (e.g., for model training)
Get the current state (including ‘stacked’ frames if the model’s input includes more than one frame at a time)
Experiences in the model are stored using a 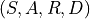 format using the function
format using the function self.memory.add():
To sample the replay buffer, the function self.memory.sample() is used:
This function returns a batch of size batch_size in the format 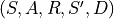 .
.
Note
Because samples may sometimes be drawn on the boundaries of episodes, an additional parameter valid is returned here. This ensured that if losses are computed from this sample, “invalid” batches (i.e., those crossing episode boundaries) do not affect the losses.